Swop Exporter Not Working Again Failed to Connect to Server
Applies to openSUSE Bound 15.3
17 Mutual bug and their solutions #Edit source
This chapter describes a range of potential problems and their solutions. Even if your situation is not precisely listed hither, in that location may be 1 like enough to offer hints to the solution of your trouble.
Linux reports things in a very detailed way. There are several places to expect when you encounter issues with your system, near of which are standard to Linux systems in general, and some are relevant to openSUSE Spring systems. Most log files can be viewed with YaST ( › ).
YaST offers the possibility to collect all arrangement data needed by the support team. Use › and select the problem category. When all information is gathered, attach it to your support request.
A list of the most frequently checked log files follows with the description of their typical purpose. Paths containing ~ refer to the current user'southward dwelling directory.
Table 17.1: Log files #
| Log File | Description |
|---|---|
| | Messages from the desktop applications currently running. |
| | Log files from AppArmor, encounter Book "Security and Hardening Guide" for detailed information. |
| | Log file from Inspect to track whatsoever admission to files, directories, or resources of your system, and trace organization calls. Run across Book "Security and Hardening Guide" for detailed information. |
| | Messages from the mail system. |
| | Log file from NetworkManager to collect problems with network connectivity |
| | Directory containing Samba server and customer log messages. |
| | All letters from the kernel and organisation log daemon with the "warning" level or college. |
| | Binary file containing user login records for the current machine session. View it with |
| | Various showtime-upward and runtime log files from the X Window System. It is useful for debugging failed Ten start-ups. |
| | Directory containing YaST's actions and their results. |
| | Log file of Zypper. |
Apart from log files, your automobile also supplies you with information well-nigh the running system. See Tabular array 17.2: System information with the /proc file system
Table 17.2: System information with the /proc file arrangement #
| File | Description |
|---|---|
| | Contains processor data, including its type, brand, model, and functioning. |
| | Shows which DMA channels are currently beingness used. |
| | Shows which interrupts are in utilise, and how many of each accept been in utilize. |
| | Displays the status of I/O (input/output) memory. |
| | Shows which I/O ports are in utilise at the moment. |
| | Displays memory status. |
| | Displays the individual modules. |
| | Displays devices currently mounted. |
| | Shows the partitioning of all difficult disks. |
| | Displays the electric current version of Linux. |
Autonomously from the /proc file organisation, the Linux kernel exports data with the sysfs module, an in-retention file organisation. This module represents kernel objects, their attributes and relationships. For more than information about sysfs, meet the context of udev in Book "Reference", Chapter sixteen "Dynamic kernel device management with udev". Table 17.3 contains an overview of the most common directories under /sys.
Table 17.iii: Arrangement information with the /sys file organization #
| File | Description |
|---|---|
| | Contains subdirectories for each block device discovered in the system. By and large, these are mostly deejay blazon devices. |
| | Contains subdirectories for each physical bus blazon. |
| | Contains subdirectories grouped together as a functional types of devices (like graphics, net, printer, etc.) |
| | Contains the global device hierarchy. |
Linux comes with several tools for organisation analysis and monitoring. See Book "Arrangement Assay and Tuning Guide", Chapter two "System monitoring utilities" for a selection of the most important ones used in system diagnostics.
Each of the post-obit scenarios begins with a header describing the trouble followed by a paragraph or ii offering suggested solutions, available references for more detailed solutions, and cross-references to other scenarios that are related.
Boot problems are situations when your organisation does not boot properly (does not boot to the expected target and login screen).
If the hardware is functioning properly, it is possible that the boot loader is corrupted and Linux cannot start on the machine. In this case, it is necessary to repair the boot loader. To do then, you demand to start the Rescue Organisation as described in Department 17.five.2, "Using the rescue organisation" and follow the instructions in Section 17.v.two.4, "Modifying and re-installing the boot loader".
Alternatively, yous can apply the Rescue System to gear up the boot loader equally follows. Boot your automobile from the installation media. In the boot screen, choose › . Select the disk containing the installed arrangement and kernel with the default kernel options.
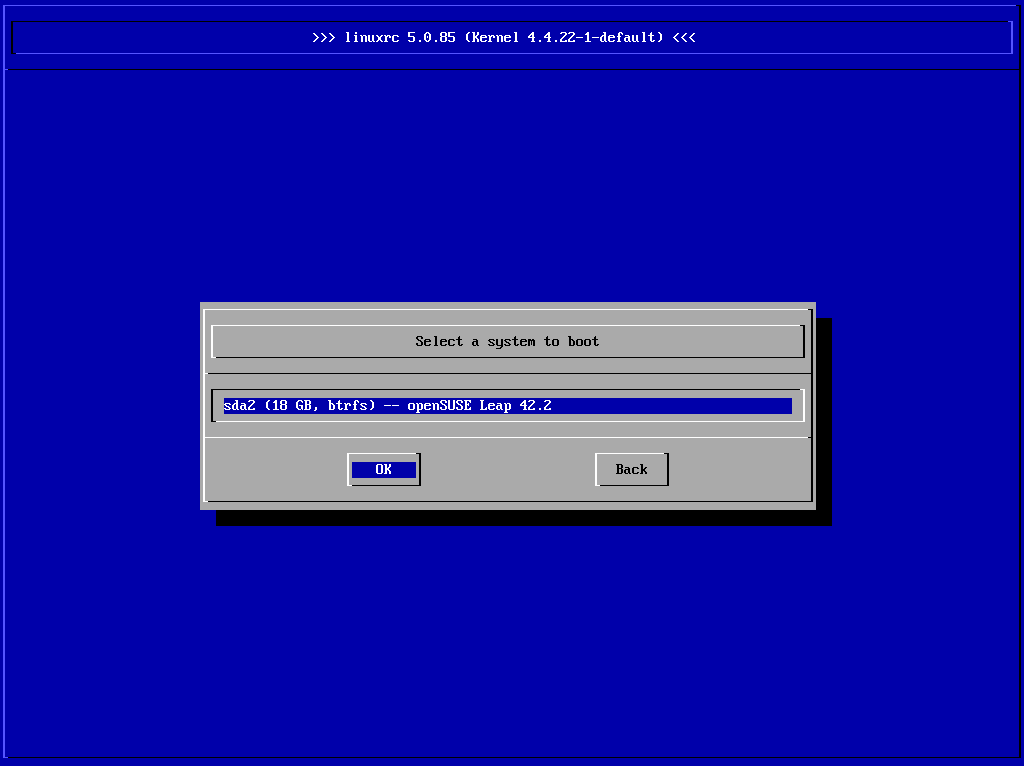
Figure 17.one: Select disk #
When the system is booted, start YaST and switch to › . Brand certain that the pick is enabled, and click . This fixes the corrupted boot loader by overwriting it, or installs the boot loader if it is missing.
Other reasons for the machine non booting may be BIOS-related:
- BIOS settings
-
Check your BIOS for references to your hard disk. Chow two may simply not be started if the hd itself cannot be found with the current BIOS settings.
- BIOS boot order
-
Check whether your system's kick order includes the hard disk. If the hard disk option was not enabled, your organization may install properly, but fails to boot when access to the hard disk is required.
This behavior typically occurs after a failed kernel upgrade and it is known as a kernel panic because of the type of error on the system console that sometimes can be seen at the last stage of the process. If, in fact, the auto has just been rebooted following a software update, the immediate goal is to reboot information technology using the old, proven version of the Linux kernel and associated files. This can be done in the Chow 2 boot loader screen during the boot process every bit follows:
-
Reboot the calculator using the reset push, or switch it off and on again.
-
When the Chow 2 kick screen becomes visible, select the entry and choose the previous kernel from the menu. The machine will boot using the prior version of the kernel and its associated files.
-
After the boot process has completed, remove the newly installed kernel and, if necessary, set the default boot entry to the erstwhile kernel using the YaST module. For more information refer to Volume "Reference", Chapter 12 "The kicking loader GRUB two", Department 12.3 "Configuring the boot loader with YaST". However, doing this is probably not necessary because automated update tools ordinarily modify it for you during the rollback process.
-
Reboot.
If this does not fix the problem, kicking the computer using the installation media. After the auto has booted, continue with Step 3.
If the auto starts, but does not boot into the graphical login director, anticipate problems either with the selection of the default systemd target or the configuration of the Ten Window System. To check the current systemd default target run the command sudo systemctl get-default. If the value returned is not graphical.target, run the command sudo systemctl isolate graphical.target. If the graphical login screen starts, log in and start › › and ready the to . From now on the arrangement should boot into the graphical login screen.
If the graphical login screen does not showtime even if having booted or switched to the graphical target, your desktop or X Window software is probably misconfigured or corrupted. Examine the log files at /var/log/Xorg.*.log for detailed messages from the Ten server as it attempted to start. If the desktop fails during start, it may log mistake letters to the organization journal that can be queried with the control journalctl (see Book "Reference", Chapter 11 "journalctl: Query the systemd journal" for more than information). If these fault letters hint at a configuration problem in the X server, attempt to gear up these issues. If the graphical system still does not come upwards, consider reinstalling the graphical desktop.
If a btrfs root partitioning becomes corrupted, try the following options:
-
Mountain the partition with the
-o recoverypick. -
If that fails, run
btrfs-zero-logon your root partition.
If the root partition becomes corrupted, apply the parameter forcefsck on the boot prompt. This passes the option -f (strength) to the fsck command.
When a swap device is non available and the system cannot enable information technology during kick, booting may fail. Try disabling all swap devices by appending the post-obit options to the kernel command line:
systemd.device_wants_unit=off systemd.mask=swap.target
You lot may also effort disabling specific swap devices:
systemd.mask=dev-sda1.swap
17.two.seven Grub ii fails during reboot on a dual-boot system #Edit source
If Chow 2 fails during reboot, disable the Fast Kicking setting in the BIOS.
Login issues occur when your machine does boot to the expected welcome screen or login prompt, but refuses to accept the user name and password, or accepts them but then does not carry properly (fails to get-go the graphic desktop, produces errors, drops to a command line, etc.).
17.iii.1 Valid user name and password combinations fail #Edit source
This normally occurs when the system is configured to utilize network authentication or directory services and, for some reason, cannot call back results from its configured servers. The root user, as the simply local user, is the only user that can all the same log in to these machines. The following are some common reasons a machine appears functional but cannot process logins correctly:
-
The network is not working. For farther directions on this, turn to Section 17.4, "Network bug".
-
DNS is not working at the moment (which prevents GNOME from working and the arrangement from making validated requests to secure servers). I indication that this is the instance is that the machine takes an extremely long fourth dimension to respond to whatsoever activity. Detect more data about this topic in Section 17.iv, "Network problems".
-
If the arrangement is configured to utilize Kerberos, the system'southward local time may have drifted past the accepted variance with the Kerberos server time (this is typically 300 seconds). If NTP (network fourth dimension protocol) is not working properly or local NTP servers are not working, Kerberos authentication ceases to part because it depends on common clock synchronization across the network.
-
The arrangement's authentication configuration is misconfigured. Check the PAM configuration files involved for any typographical errors or misordering of directives. For additional groundwork information nigh PAM and the syntax of the configuration files involved, refer to Book "Security and Hardening Guide", Affiliate 3 "Authentication with PAM".
-
The dwelling partition is encrypted. Find more information about this topic in Section 17.three.3, "Login to encrypted home sectionalization fails".
In all cases that do not involve external network problems, the solution is to reboot the system into single-user mode and repair the configuration before booting again into operating mode and attempting to log in over again. To kicking into single-user mode:
-
Reboot the system. The kicking screen appears, offering a prompt.
-
Printing Esc to exit the splash screen and go to the GRUB 2 text-based carte.
-
Printing B to enter the Chow 2 editor.
-
Add together the following parameter to the line containing the kernel parameters:
systemd.unit=rescue.target
-
Press F10.
-
Enter the user name and password for
root. -
Brand all the necessary changes.
-
Kicking into the full multiuser and network mode by entering
systemctl isolate graphical.targetat the control line.
17.3.2 Valid user name and countersign not accepted #Edit source
This is by far the almost mutual problem users encounter, because there are many reasons this can occur. Depending on whether yous use local user direction and hallmark or network authentication, login failures occur for dissimilar reasons.
Local user direction can fail for the post-obit reasons:
-
The user may have entered the wrong password.
-
The user's dwelling directory containing the desktop configuration files is corrupted or write protected.
-
There may be problems with the 10 Window System authenticating this particular user, particularly if the user'south home directory has been used with another Linux distribution prior to installing the current one.
To locate the reason for a local login failure, proceed as follows:
-
Check whether the user remembered their password correctly before yous kickoff debugging the whole hallmark mechanism. If the user may accept not have remembered their password correctly, use the YaST User Management module to change the user's password. Pay attention to the Caps Lock key and unlock information technology, if necessary.
-
Log in as
rootand check the system journal withjournalctl -efor error letters of the login process and of PAM. -
Try to log in from a panel (using Ctrl – Alt – F1). If this is successful, the blame cannot be put on PAM, because it is possible to authenticate this user on this motorcar. Try to locate whatever problems with the X Window System or the GNOME desktop. For more information, refer to Section 17.3.four, "GNOME desktop has issues".
-
If the user'due south home directory has been used with another Linux distribution, remove the
Xauthorityfile in the user's habitation. Use a panel login via Ctrl – Alt – F1 and runrm .Xauthorityas this user. This should eliminate X authentication problems for this user. Try graphical login once again. -
If the desktop could not start because of corrupt configuration files, keep with Section 17.3.4, "GNOME desktop has bug".
In the post-obit, mutual reasons a network hallmark for a particular user may neglect on a specific machine are listed:
-
The user may take entered the wrong password.
-
The user proper noun exists in the machine's local authentication files and is likewise provided by a network hallmark system, causing conflicts.
-
The dwelling house directory exists but is corrupt or unavailable. Mayhap it is write protected or is on a server that is inaccessible at the moment.
-
The user does not have permission to log in to that particular host in the authentication arrangement.
-
The automobile has inverse host names, for whatever reason, and the user does not accept permission to log in to that host.
-
The machine cannot achieve the authentication server or directory server that contains that user's information.
-
At that place may be problems with the 10 Window System authenticating this item user, specially if the user'due south home has been used with another Linux distribution prior to installing the current i.
To locate the cause of the login failures with network authentication, proceed as follows:
-
Check whether the user remembered their password correctly before you lot start debugging the whole authentication machinery.
-
Determine the directory server which the machine relies on for hallmark and make sure that it is up and running and properly communicating with the other machines.
-
Make up one's mind that the user's user name and password work on other machines to make sure that their hallmark data exists and is properly distributed.
-
Encounter if another user tin can log in to the misbehaving automobile. If some other user can log in without difficulty or if
roottin can log in, log in and examine the arrangement periodical withjournalctl -due east> file. Locate the time stamps that stand for to the login attempts and make up one's mind if PAM has produced any fault messages. -
Endeavour to log in from a console (using Ctrl – Alt – F1). If this is successful, the problem is not with PAM or the directory server on which the user's dwelling is hosted, because information technology is possible to authenticate this user on this machine. Try to locate any problems with the X Window System or the GNOME desktop. For more information, refer to Section 17.three.4, "GNOME desktop has problems".
-
If the user'southward home directory has been used with another Linux distribution, remove the
Xauthorityfile in the user'southward abode. Utilize a console login via Ctrl – Alt – F1 and runrm .Xauthorityas this user. This should eliminate Ten authentication problems for this user. Attempt graphical login again. -
If the desktop could not start considering of corrupt configuration files, continue with Section 17.3.4, "GNOME desktop has issues".
It is recommended to use an encrypted home partition for laptops. If you cannot log in to your laptop, the reason is normally elementary: your partition could not exist unlocked.
During the kick time, you need to enter the passphrase to unlock your encrypted division. If you do not enter it, the kick process continues, leaving the partition locked.
To unlock your encrypted sectionalisation, go along as follows:
-
Switch to the text panel with Ctrl – Alt – F1.
-
Become
root. -
Restart the unlocking process again with:
root #systemctl restart home.mount -
Enter your passphrase to unlock your encrypted partition.
-
Get out the text console and switch back to the login screen with Alt – F7.
-
Log in every bit usual.
If you are experiencing issues with the GNOME desktop, in that location are several means to troubleshoot the misbehaving graphical desktop surroundings. The recommended process described below offers the safest choice to fix a broken GNOME desktop.
Procedure 17.1: Troubleshooting GNOME #
-
Launch YaST and switch to .
-
Open up the dialog and click .
-
Fill out the required fields and click to create a new user.
-
Log out and log in equally the new user. This gives you a fresh GNOME environment.
-
Copy private subdirectories from the
~/.local/and~/.config/directories of the old user account to the respective directories of the new user business relationship.Log out and log in again as the new user afterward every copy performance to check whether GNOME still works correctly.
-
Repeat the previous pace until you notice the configuration file that breaks GNOME.
-
Log in as the quondam user, and move the offending configuration file to a different location. Log out and log in again equally the old user.
-
Delete the previously created user.
Many problems of your system may be network-related, even though they do not seem to be at first. For example, the reason for a organization not allowing users to log in may be a network problem of some kind. This department introduces a simple checklist you lot can apply to place the cause of any network problem encountered.
Procedure 17.2: How to identify network problems #
When checking the network connection of your machine, go on as follows:
-
If you use an Ethernet connectedness, check the hardware first. Make sure that your network cable is properly plugged into your computer and router (or hub, etc.). The command lights next to your Ethernet connector are normally both be agile.
If the connection fails, cheque whether your network cablevision works with some other car. If information technology does, your network carte causes the failure. If hubs or switches are included in your network setup, they may be faulty, as well.
-
If using a wireless connection, bank check whether the wireless link tin can be established by other machines. If not, contact the wireless network's ambassador.
-
When you take checked your basic network connectivity, attempt to find out which service is non responding. Gather the address information of all network servers needed in your setup. Either look them up in the advisable YaST module or ask your arrangement administrator. The following listing gives some typical network servers involved in a setup together with the symptoms of an outage.
- DNS (name service)
-
A broken or malfunctioning name service affects the network'south functionality in many ways. If the local machine relies on any network servers for authentication and these servers cannot be constitute because of name resolution issues, users would not even be able to log in. Machines in the network managed past a broken proper noun server would not be able to "meet" each other and communicate.
- NTP (time service)
-
A malfunctioning or completely broken NTP service could affect Kerberos hallmark and 10 server functionality.
- NFS (file service)
-
If any application needs data stored in an NFS mounted directory, information technology cannot start or function properly if this service was downwardly or misconfigured. In the worst case scenario, a user's personal desktop configuration would non come up upward if their domicile directory containing the
.gconfsubdirectory could not be found because of a faulty NFS server. - Samba (file service)
-
If any awarding needs data stored in a directory on a faulty Samba server, it cannot kickoff or function properly.
- NIS (user management)
-
If your openSUSE Spring system relies on a faulty NIS server to provide the user information, users cannot log in to this motorcar.
- LDAP (user management)
-
If your openSUSE Spring arrangement relies on a faulty LDAP server to provide the user data, users cannot log in to this automobile.
- Kerberos (hallmark)
-
Hallmark will non piece of work and login to any auto fails.
- CUPS (network press)
-
Users cannot print.
-
Check whether the network servers are running and whether your network setup allows you to establish a connection:

Of import: Limitations
The debugging procedure described below but applies to a uncomplicated network server/client setup that does not involve any internal routing. It assumes both server and customer are members of the same subnet without the need for additional routing.
-
Apply
pingIP_ADDRESS/HOSTNAME (supplant with the host name or IP address of the server) to cheque whether each one of them is up and responding to the network. If this command is successful, it tells you lot that the host you lot were looking for is up and running and that the name service for your network is configured correctly.If ping fails with
destination host unreachable, either your organisation or the desired server is not properly configured or down. Bank check whether your organization is reachable by runningpingIP address or YOUR_HOSTNAME from another auto. If you can reach your machine from some other machine, it is the server that is not running or non configured correctly.If ping fails with
unknown host, the name service is non configured correctly or the host name used was incorrect. For farther checks on this matter, refer to Pace 4.b. If ping withal fails, either your network menu is not configured correctly or your network hardware is faulty. -
Apply
hostHOSTNAME to check whether the host name of the server yous are trying to connect to is properly translated into an IP address and vice versa. If this command returns the IP address of this host, the name service is upward and running. If thehostcommand fails, bank check all network configuration files relating to name and accost resolution on your host:-
/var/run/netconfig/resolv.conf -
This file is used to proceed runway of the proper name server and domain yous are currently using. Information technology is a symbolic link to
/run/netconfig/resolv.confand is usually automatically adapted by YaST or DHCP. Make sure that this file has the post-obit construction and all network addresses and domain names are right:search FULLY_QUALIFIED_DOMAIN_NAME nameserver IPADDRESS_OF_NAMESERVER
This file can contain more than than one name server address, just at least one of them must exist correct to provide proper name resolution to your host. If needed, adjust this file using the YaST Network Settings module (Hostname/DNS tab).
If your network connexion is handled via DHCP, enable DHCP to change host name and name service information by selecting (can exist ready globally for any interface or per interface) and in the YaST Network Settings module (Hostname/DNS tab).
-
/etc/nsswitch.conf -
This file tells Linux where to wait for name service information. It should look similar this:
... hosts: files dns networks: files dns ...
The
dnsentry is vital. It tells Linux to use an external proper noun server. Normally, these entries are automatically managed by YaST, but it would be prudent to check.If all the relevant entries on the host are correct, let your system administrator bank check the DNS server configuration for the correct zone data. For detailed information about DNS, refer to Book "Reference", Chapter nineteen "The domain name system". If yous have made sure that the DNS configuration of your host and the DNS server are correct, proceed with checking the configuration of your network and network device.
-
-
If your system cannot establish a connection to a network server and you have excluded name service bug from the list of possible culprits, cheque the configuration of your network card.
Apply the control
ip addr bear witnessNETWORK_DEVICE to cheque whether this device was properly configured. Make sure that theinet accostwith the netmask (/MASK) is configured correctly. An fault in the IP address or a missing bit in your network mask would render your network configuration unusable. If necessary, perform this bank check on the server as well. -
If the name service and network hardware are properly configured and running, but some external network connections still go long time-outs or fail entirely, use
tracerouteFULLY_QUALIFIED_DOMAIN_NAME (executed asroot) to track the network road these requests are taking. This command lists any gateway (hop) that a request from your machine passes on its way to its destination. Information technology lists the response fourth dimension of each hop and whether this hop is reachable. Use a combination of traceroute and ping to rails downwardly the culprit and allow the administrators know.
-
When yous have identified the cause of your network trouble, you can resolve it yourself (if the problem is located on your motorcar) or let the system administrators of your network know almost your findings so they can reconfigure the services or repair the necessary systems.
If yous take a problem with network connectivity, narrow it down equally described in Process 17.2, "How to identify network problems". If NetworkManager seems to be the culprit, proceed equally follows to get logs providing hints on why NetworkManager fails:
-
Open up a beat out and log in as
root. -
Restart the NetworkManager:
tux >sudosystemctl restart NetworkManager -
Open a Web folio, for example, http://world wide web.opensuse.org as normal user to see, if yous can connect.
-
Collect any information nigh the country of NetworkManager in
/var/log/NetworkManager.
For more data about NetworkManager, refer to Book "Reference", Chapter 28 "Using NetworkManager".
Data problems are when the motorcar may or may not boot properly but, in either instance, it is clear that there is information corruption on the organisation and that the system needs to be recovered. These situations call for a fill-in of your critical data, enabling you to recover the organization land from earlier your arrangement failed.
Sometimes yous need to perform a fill-in from an entire partition or even hd. Linux comes with the dd tool which tin create an verbal re-create of your disk. Combined with gzip y'all salvage some space.
Procedure 17.3: Backing upwardly and restoring difficult disks #
-
Showtime a Shell as user
root. -
Select your source device. Typically this is something like
/dev/sda(labeled as SOURCE). -
Decide where you want to shop your image (labeled as BACKUP_PATH). It must be different from your source device. In other words: if you make a backup from
/dev/sda, your prototype file must not to be stored nether/dev/sda. -
Run the commands to create a compressed prototype file:
root #dd if=/dev/SOURCE | gzip > /BACKUP_PATH/image.gz -
Restore the difficult disk with the following commands:
root #gzip -dc /BACKUP_PATH/image.gz | dd of=/dev/SOURCE
If you only need to support a partition, replace the SOURCE placeholder with your corresponding sectionalisation. In this case, your image file can lie on the aforementioned hd, but on a different division.
There are several reasons a system could fail to come up and run properly. A corrupted file arrangement following a system crash, corrupted configuration files, or a corrupted boot loader configuration are the most common ones.
To help y'all to resolve these situations, openSUSE Bound contains a rescue system that you can boot. The rescue system is a pocket-sized Linux system that can exist loaded into a RAM disk and mounted as root file system, allowing you to access your Linux partitions from the outside. Using the rescue system, you can recover or modify any of import aspect of your organisation.
-
Dispense any type of configuration file.
-
Check the file system for defects and start automated repair processes.
-
Access the installed system in a "change root" environs.
-
Bank check, modify, and re-install the kick loader configuration.
-
Recover from a badly installed device driver or unusable kernel.
-
Resize partitions using the parted control. Notice more than data about this tool at the GNU Parted Spider web site http://www.gnu.org/software/parted/parted.html.
The rescue system can be loaded from various sources and locations. The simplest selection is to boot the rescue system from the original installation medium.
-
Insert the installation medium into your DVD drive.
-
Reboot the system.
-
At the boot screen, printing F4 and choose . So cull from the main bill of fare.
-
Enter
rootat theRescue:prompt. A countersign is not required.
If your hardware setup does not include a DVD drive, you can kicking the rescue system from a network source. The following example applies to a remote kicking scenario—if using another kicking medium, such as a DVD, modify the info file accordingly and kicking as you would for a normal installation.
-
Enter the configuration of your PXE kick setup and add the lines
install=PROTOCOL://INSTSOURCEandrescue=ane. If you lot need to outset the repair system, userepair=1instead. As with a normal installation, PROTOCOL stands for any of the supported network protocols (NFS, HTTP, FTP, etc.) and INSTSOURCE for the path to your network installation source. -
Boot the system using "Wake on LAN".
-
Enter
rootat theRescue:prompt. A password is not required.
When y'all have entered the rescue system, you can apply the virtual consoles that can be reached with Alt – F1 to Alt – F6.
A shell and other useful utilities, such as the mount program, are available in the /bin directory. The /sbin directory contains important file and network utilities for reviewing and repairing the file system. This directory also contains the most of import binaries for system maintenance, such every bit fdisk, mkfs, mkswap, mount, and shutdown, ip and ss for maintaining the network. The directory /usr/bin contains the vi editor, notice, less, and SSH.
To see the system letters, either use the control dmesg or view the organisation log with journalctl.
17.5.ii.1 Checking and manipulating configuration files #Edit source
As an example for a configuration that might be fixed using the rescue system, imagine you have a broken configuration file that prevents the system from booting properly. You can fix this using the rescue organization.
To manipulate a configuration file, proceed as follows:
-
Start the rescue system using ane of the methods described higher up.
-
To mount a root file arrangement located under
/dev/sda6to the rescue system, utilise the following command:tux >sudomountain /dev/sda6 /mntAll directories of the system are now located nether
/mnt -
Alter the directory to the mounted root file system:
-
Open the problematic configuration file in the 6 editor. Accommodate and save the configuration.
-
Unmount the root file system from the rescue arrangement:
-
Reboot the auto.
Generally, file systems cannot be repaired on a running organization. If you run across serious problems, you lot may non even exist able to mount your root file system and the system boot may end with a "kernel panic". In this instance, the merely mode is to repair the organisation from the outside. The system contains the utilities to check and repair the btrfs, ext2, ext3, ext4, xfs, dosfs, and vfat file systems. Look for the command fsck.FILESYSTEM . For example, if yous need a file system check for btrfs, utilize fsck.btrfs.
If you demand to admission the installed system from the rescue system, you need to do this in a modify root surroundings. For example, to modify the boot loader configuration, or to execute a hardware configuration utility.
To ready a alter root environs based on the installed system, proceed as follows:
-

Tip: Import LVM volume groups
If you lot are using an LVM setup (refer to Book "Reference", Chapter 5 "", Department 5.2 "LVM configuration" for more full general details), import all existing book groups to be able to detect and mount the device(s):
Run
lsblkto check which node corresponds to the root partition. It is/dev/sda2in our example:tux >lsblk Proper name MAJ:MIN RM SIZE RO Type MOUNTPOINT sda 8:0 0 149,1G 0 disk ├─sda1 8:ane 0 2G 0 part [SWAP] ├─sda2 8:2 0 20G 0 role / └─sda3 viii:three 0 127G 0 part └─cr_home 254:0 0 127G 0 crypt /dwelling house -
Mount the root partition from the installed system:
tux >sudomount /dev/sda2 /mnt -
Mount
/proc,/dev, and/syspartitions:tux >sudomount -t proc none /mnt/proctux >sudomountain --rbind /dev /mnt/devtux >sudomountain --rbind /sys /mnt/sys -
Now you can "change root" into the new environment, keeping the
bashshell:tux >chroot /mnt /bin/bash -
Finally, mount the remaining partitions from the installed arrangement:
-
Now you take admission to the installed arrangement. Before rebooting the system, unmount the partitions with
umount-aand exit the "change root" environment withexit.
![]()
Alert: Limitations
Although you accept full access to the files and applications of the installed system, at that place are some limitations. The kernel that is running is the one that was booted with the rescue system, not with the modify root environment. It only supports essential hardware and it is non possible to add together kernel modules from the installed organisation unless the kernel versions are identical. Always check the version of the currently running (rescue) kernel with uname -r and then find out if a matching subdirectory exists in the /lib/modules directory in the change root environment. If yeah, you can use the installed modules, otherwise you need to supply their right versions on other media, such as a flash disk. Most often the rescue kernel version differs from the installed 1 — then you cannot simply access a sound card, for example. It is likewise non possible to start a graphical user interface.
As well note that y'all leave the "change root" environment when you switch the panel with Alt – F1 to Alt – F6.
17.5.2.4 Modifying and re-installing the boot loader #Edit source
Sometimes a organisation cannot boot because the kicking loader configuration is corrupted. The start-up routines cannot, for example, translate physical drives to the actual locations in the Linux file system without a working kicking loader.
To check the kicking loader configuration and re-install the boot loader, continue as follows:
-
Perform the necessary steps to admission the installed arrangement as described in Section 17.five.2.iii, "Accessing the installed system".
-
Cheque that the Chow ii kick loader is installed on the arrangement. If not, install the packet
grub2and runtux >sudogrub2-install /dev/sda -
Check whether the post-obit files are correctly configured co-ordinate to the GRUB ii configuration principles outlined in Volume "Reference", Chapter 12 "The boot loader GRUB 2" and apply fixes if necessary.
-
/etc/default/chow -
/boot/grub2/device.map(optional file, only present if created manually) -
/kick/grub2/grub.cfg(this file is generated, do not edit) -
/etc/sysconfig/bootloader
-
-
Re-install the kick loader using the post-obit control sequence:
tux >sudogrub2-mkconfig -o /boot/grub2/chow.cfg -
Unmount the partitions, log out from the "change root" environment, and reboot the organisation:
tux >umount -a exit reboot
A kernel update may introduce a new bug which can impact the operation of your system. For example a driver for a piece of hardware in your system may exist faulty, which prevents you from accessing and using information technology. In this example, revert to the last working kernel (if available on the system) or install the original kernel from the installation media.
![]()
Tip: How to keep last kernels subsequently update
To forbid failures to boot later on a faulty kernel update, use the kernel multiversion characteristic and tell libzypp which kernels you desire to proceed afterward the update.
For example to always keep the last two kernels and the currently running one, add
multiversion.kernels = latest,latest-1,running
to the /etc/zypp/zypp.conf file. See Book "Reference", Chapter six "Installing multiple kernel versions" for more than information.
A like example is when you need to re-install or update a cleaved commuter for a device not supported by openSUSE Leap . For example when a hardware vendor uses a specific device, such as a hardware RAID controller, which needs a binary commuter to be recognized by the operating organization. The vendor typically releases a Driver Update Disk (DUD) with the fixed or updated version of the required driver.
In both cases you need to access the installed system in the rescue mode and fix the kernel related problem, otherwise the system may fail to boot correctly:
-
Kick from the openSUSE Leap installation media.
-
If you are recovering after a faulty kernel update, skip this step. If you lot need to employ a driver update disk (DUD), press F6 to load the driver update subsequently the boot menu appears, and choose the path or URL to the commuter update and confirm with .
-
Cull from the boot menu and printing Enter. If you chose to utilise DUD, you will be asked to specify where the commuter update is stored.
-
Enter
rootat theRescue:prompt. A password is not required. -
Manually mountain the target system and "change root" into the new environment. For more than information, come across Department 17.5.ii.iii, "Accessing the installed system".
-
If using DUD, install/re-install/update the faulty device driver package. Ever brand sure the installed kernel version exactly matches the version of the driver you are installing.
If fixing faulty kernel update installation, yous tin can install the original kernel from the installation media with the following procedure.
-
Identify your DVD device with
hwinfo --cdromand mount it withmount /dev/sr0 /mnt. -
Navigate to the directory where your kernel files are stored on the DVD, for example
cd /mnt/suse/x86_64/. -
Install required
kernel-*,kernel-*-base, andkernel-*-extrapackages of your flavor with therpm -icommand.
-
-
Update configuration files and reinitialize the kicking loader if needed. For more than information, run across Section 17.5.ii.4, "Modifying and re-installing the kick loader".
-
Remove whatever bootable media from the arrangement bulldoze and reboot.
Source: https://doc.opensuse.org/documentation/leap/startup/html/book-startup/cha-trouble.html
0 Response to "Swop Exporter Not Working Again Failed to Connect to Server"
Post a Comment